scale-tone

Message Queueing vs. Event Stream Processing in Azure.
Yet another customer got confused and went in wrong direction with various Messaging products (more specifically, with Event Hubs) in Azure, so I finally forced myself to write down some of the typical arguments I hear from them and how I typically try to prove those arguments wrong. My first intention was to call this post something like “Fallacies of Messaging in Azure”, but then I remembered that I’m not yet L. Peter Deutsch. So let’s just call them false assumptions and see what they can lead to in practice.
NOTE1: No, I’m not trying to say that e.g. Service Bus is anyhow “better” than e.g. Event Hubs. I’m just highlighting important architectural differences, to once again underscore the importance of picking the right tool for the job and avoiding any sort of Cargo cult when making decisions. Any below statements regarding Azure Service Bus apply more or less equally to any Message Queueing Service, while any mentioned specificities of Azure Event Hubs are more or less relevant to any Stream Processing system. For an even more generic overview of these two similar yet different concepts I greatly encourage you to watch this session from Dr. Martin Kleppmann before going further.
NOTE2: All the below demo usecases are illustrated with sample Azure Functions, that come from this GitHub repo and are written in TypeScript. Those nice blue ‘Deploy to Azure’ buttons create Function App instances along with other relevant resources (Event Hubs and Service Bus namespaces, Application Insights instances and Storage Accounts) in your Azure Subscription and deploy source code straight into there with Kudu App Service. Don’t forget to remove those resources once done.
False assumption 1. “Our service is as huge as Office365 (oh, yes, indeed!), so we need more performance, more scalability, more processing rate - more of everything! So we choose Event Hubs.”
OK, so here is a simple sample Azure Function App, with two functionally equal event handlers - EventHubHandler and ServiceBusHandler. Both do the same thing - take an event, emulate some processing activity by sleeping for 100 ms and then declare the event processed. Also the app contains this Timer-triggered function, which produces a constant flow of events towards both of those handlers. You can quickly deploy the whole test setup with this button:
It will create all relevant resources, including a Function App instance with Premium Plan, a Service Bus queue, an Event Hub with one partition in it and also a separate Application Insights instance. If you then go to that instance and monitor EventHubEventProcessed and ServiceBusEventProcessed custom metrics, it will show you a picture similar to this:
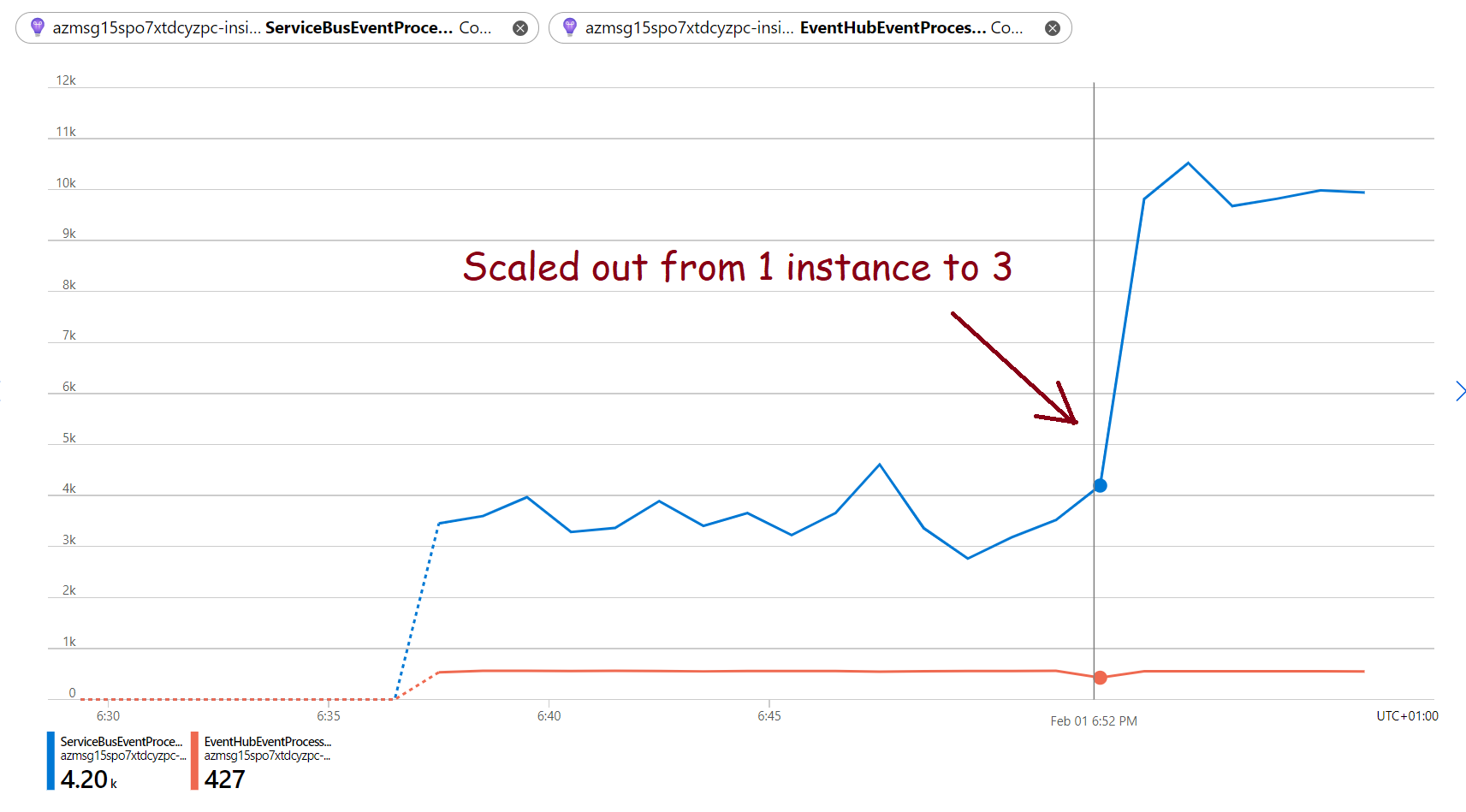
As you can see, Service Bus event processing (~60 events/sec) goes much faster than Event Hub event processing (~10 events/sec) right from the start, even with one single computing instance (that’s because even a single Functions Host efficiently parallelizes Service Bus event processing). If you then go to that Function App’s ‘Scale Out (App Service Plan)’ tab and increase instance count to e.g. 3:
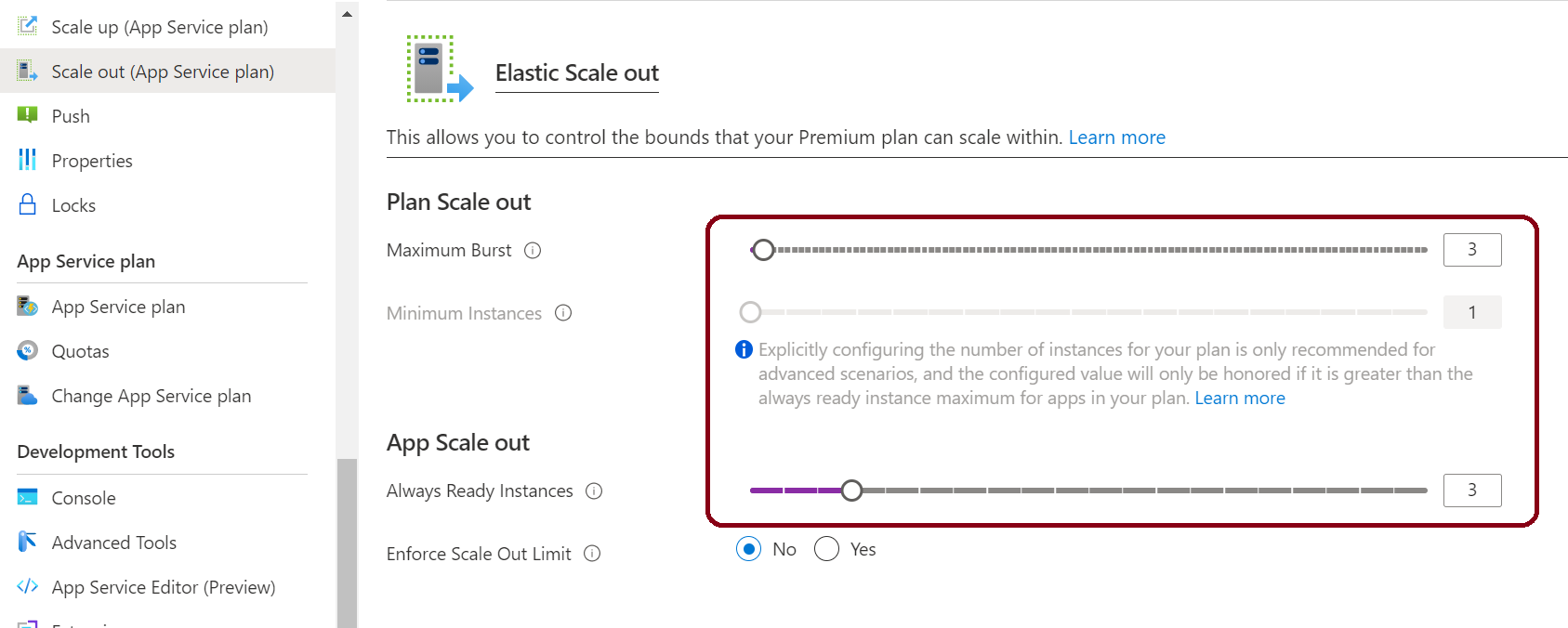
, Service Bus processing speed will increase even more, while Event Hub processing will remain same as slow.
NOTE: The above ‘Deploy to Azure’ button is intentionally instructed to deploy the sample into a Premium Plan limited to 1 processing instance, so that you can then manually scale it out. Normally the platform will scale out your Functions instance automatically, but it will not change the picture.
The reason for this behavior is that, unlike a Service Bus queue, an Event Hub partition is a data stream. You can think of it as of a magnetic tape in those early days of computing era - it is technically possible to fast-forward or rewind it, but there is no way to increase reading speed by trying to read it ‘in parallel’. With Service Bus queues you instantly speed up processing by simply adding more computing instances. With Event Hubs you can achieve something similar by increasing the number of partitions, but:
- That number is limited to 32 per hub for Standard Tier and 1024 per hub for Dedicated Tier.
- Dynamic adjustment of this number is only possible with Dedicated tier. And even in that case it is not as easy as moving a slider - might as well require reconfiguring/restarting your clients (those which are sending events). Plus, this change won’t affect those events that are already there. So if your processing side gets eventually flooded due to an uncareful planning - there’s still not much you can do.
Lesson learned: Azure Event Hubs is a tool for event stream processing, not just event processing (mind the difference). It can injest your events in enormous amounts, but keeping up with the pace when processing them is still solely your responsibility. If your injestion rate is really so huge that no Message Queueing Service can natively handle it, yet still each and every single event matters - consider hybrid scenarios like Event Hubs (for injestion) + Service Bus (for further processing), or Event Hubs (for injestion) + Stream Analytics (for aggregation) + Service Bus (for further processing), or Event Hubs (for injestion) + Event Hubs Capture (for capturing into storage files) + whatever technology you prefer for asynchronously processing those captured files.
UPD: At the same time, setting the number of partitions of your Event Hub unreasonably high can easily lead to unexpectedly high costs. Let’s say you set it to 32 in anticipation of a high ingestion rate, but your actual ingestion rate is e.g. 100 events/sec. That will only produce a tiny load of ~3 events/sec into each specific partition, and as a result, instances in your processing pipeline will be starving aka getting batches of a smaller size (simply because there isn’t enough events to form a full-sized batch, so instead of e.g. 100 events each batch will contain 3). In Consumption Mode Azure Functions Event Hub triggers are billed per batch execution => the smaller your batch is the more you pay. But more importantly, smaller batch size also leads to a higher amount of checkpointing operations (aka writing the current checkpoint cursor value into an Azure Storage blob), and that increases costs of your Storage account. To ease this particular kind of pain consider increasing the batchCheckpointFrequency setting value, so that checkpoints are written to the Storage less frequently.
False assumption 2. “We have those tiny little pieces of data that travel across our system. We call them events. So we choose Event Hubs, because it has that word in its name.”
“Event-driven” is not as simple as you might think (in fact, scientists haven’t even yet agreed on what this term really means). There’re many important architectural concepts that accompany this pattern. For example, in your real application you would typically want your event handlers to dynamically subscribe and unsubscribe to/from your event source (so that they don’t have to dig through the whole history of events first). In Service Bus this is considered first-class citizen functionality and is implemented with Topics and Subscriptions, while with Event Hubs it is much harder to achieve - you would need to configure your event processor host with EventPosition.FromEnd setting, plus reset the Offset value (with Azure Functions that would mean manually dropping the checkpoint blob from underlying Storage).
Another important concept is known as polymorphic event processing (or event routing), which in practice means, that some of your event handlers might only be interested in some specific type of event and not in all events produced by some source. And again, with Service Bus you get this feature out-of-the-box with Topic Filters, while Event Hubs do not provide anything like that, so the only option for your handler would be to read the entire stream and filter out relevant events on the client side. Here is another demo setup, that demonstrates this in practice:
That button will deploy this demo Function App, which streams events to both an Event Hub and a Service Bus Topic at the rate of 1K/sec and also handles them with its handlers. Every 1/150-th event (~0.7%) is marked as “green”, others are set to be “red”, and the handlers are only processing “green” ones. ServiceBusHandler gets “green” events only, because a correlation filter is applied to its subscription, which reduces the event rate to ridiculous ~7 events/sec, and the handler has no problem with consuming it. EventHubHandler doesn’t have that luxury and is therefore forced to pump the whole stream. Both handlers output custom metrics (ServiceBusGreenEventAgeInSec and EventHubGreenEventAgeInSec, respectively) representing event’s TTL (time difference between event creation and event processing) in seconds, and when rendered in Application Insights, those metrics would look like this:
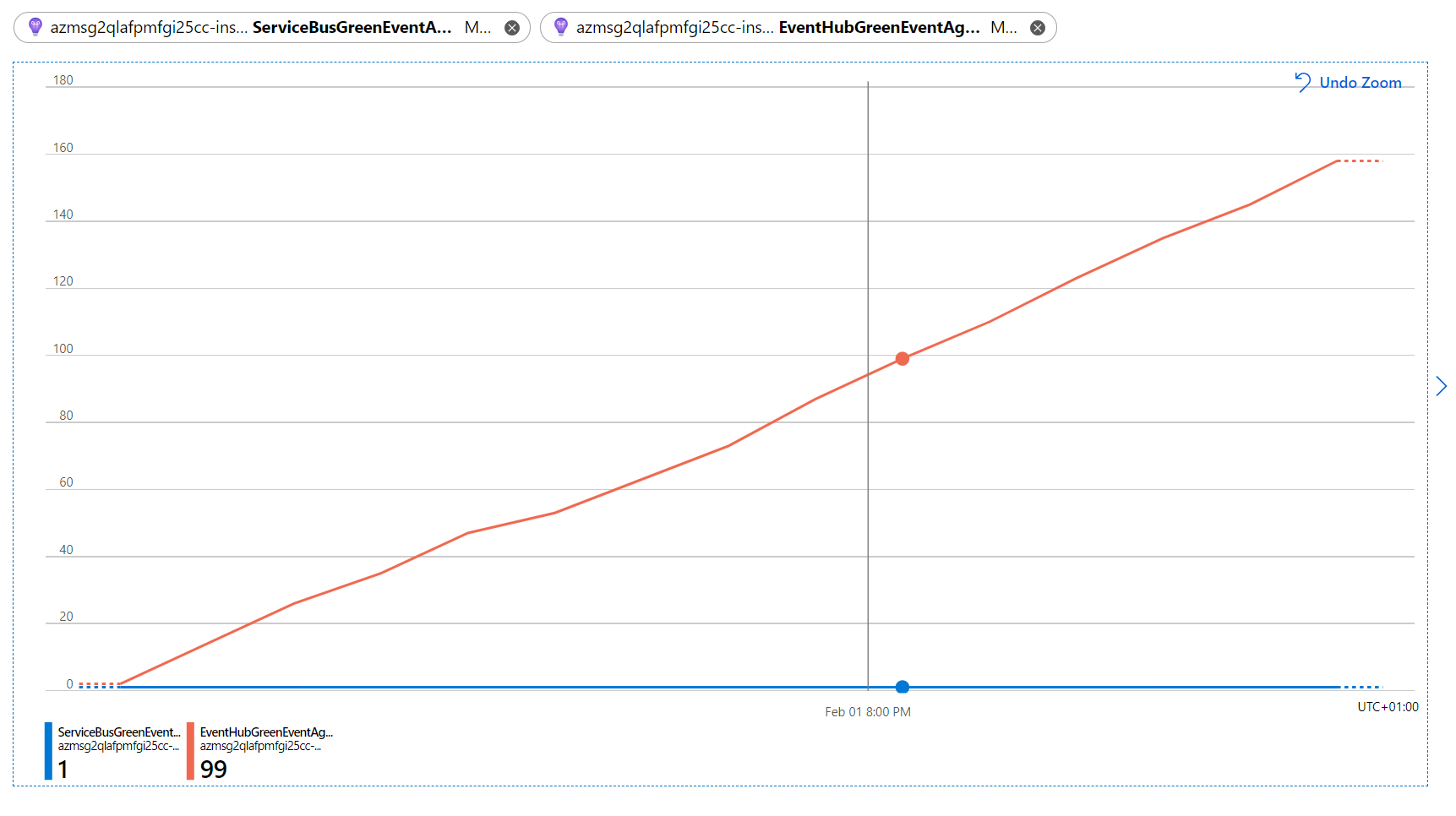
Unlike ServiceBusHandler, EventHubHandler has to deal with the entire overall rate of 1K events/sec and doesn’t seem to be able to cope with it, so the event’s TTL slowly grows (e.g. on the picture above it is already ~2 minutes behind).
To resolve this particular bottleneck in this particular scenario you could increase the batch size for your Event Hubs Trigger, so that your Functions instance can pump the stream faster. Remember though, that this streaming speed is still limited to 4096 events/sec per each Throughput Unit, and that the amount of Throughput Units is limited to 20 per namespace (unless you go for Dedicated Tier). A more generic workaround for Event Hubs would be to implement custom event routing/filtering with e.g. Azure Stream Analytics or Azure Functions.
Lesson learned: never follow the White Paper, aka never make architectural decisions based solely on naming/nomenclature/taxonomy. Try to anticipate as many functional requirements as possible and match those with specific features of chosen instrument/platform. And of course, don’t forget to try it with your own hands first.
False assumption 3. “Not only Event Hubs are bigger (whatever it means), but they also still guarantee event delivery (aka reliable). So we choose Event Hubs.”
Consider the following simple math. You have a constant ingestion rate of e.g. 100 events/sec and a processing pipeline built with Event Hubs, which is perfect in any way except that your event handler intermittently fails and needs to be retried in ~0.5% of cases (that’s in fact a pretty good reliability number of 99.5%). Under this circumstances, what the resulting processing rate could be?
Before saying that it should be exactly 100 events/sec no matter what, remember that Event Hub messages are expected to be processed in batches of some significant size (otherwise the whole purpose is defeated). And the only way to retry a single message in a batch is to retry (or more precisely, to skip checkpointing) the entire batch. So if we set this batch size to e.g. 256, then the probability for a batch to be successfully processed will be as low as (0.995 ^ 256) * 100% = ~28%. Which means, that roughly 2/3 of batches will need to be reprocessed, which increases the required processing rate (aka how fast your processing pipeline needs to be to keep up with the pace) to ~172 events/sec. Still not too much, right? But let’s see how it all behaves in reality:
This yet another demo Function App produces a constant rate of 100 events/sec and handles them with ServiceBusHandler and EventHubHandler. But now both handlers throw an exception in 0.5% of cases. A Service Bus event will in that case be automatically abandoned and retried later. For Event Hub batches the default Azure Functions behaviour is to checkpoint every batch no matter whether your handler succeeds or throws, so to make our processing reliable we need to enable Azure Functions Retry Policies by doing some extra configuration. Both handlers also output custom metrics (ServiceBusTimeSinceStartup and EventHubTimeSinceStartup) that show the time difference in seconds between app startup and the current event being processed. If you then render these metrics in the relevant Application Insights instance, the picture will be like this:
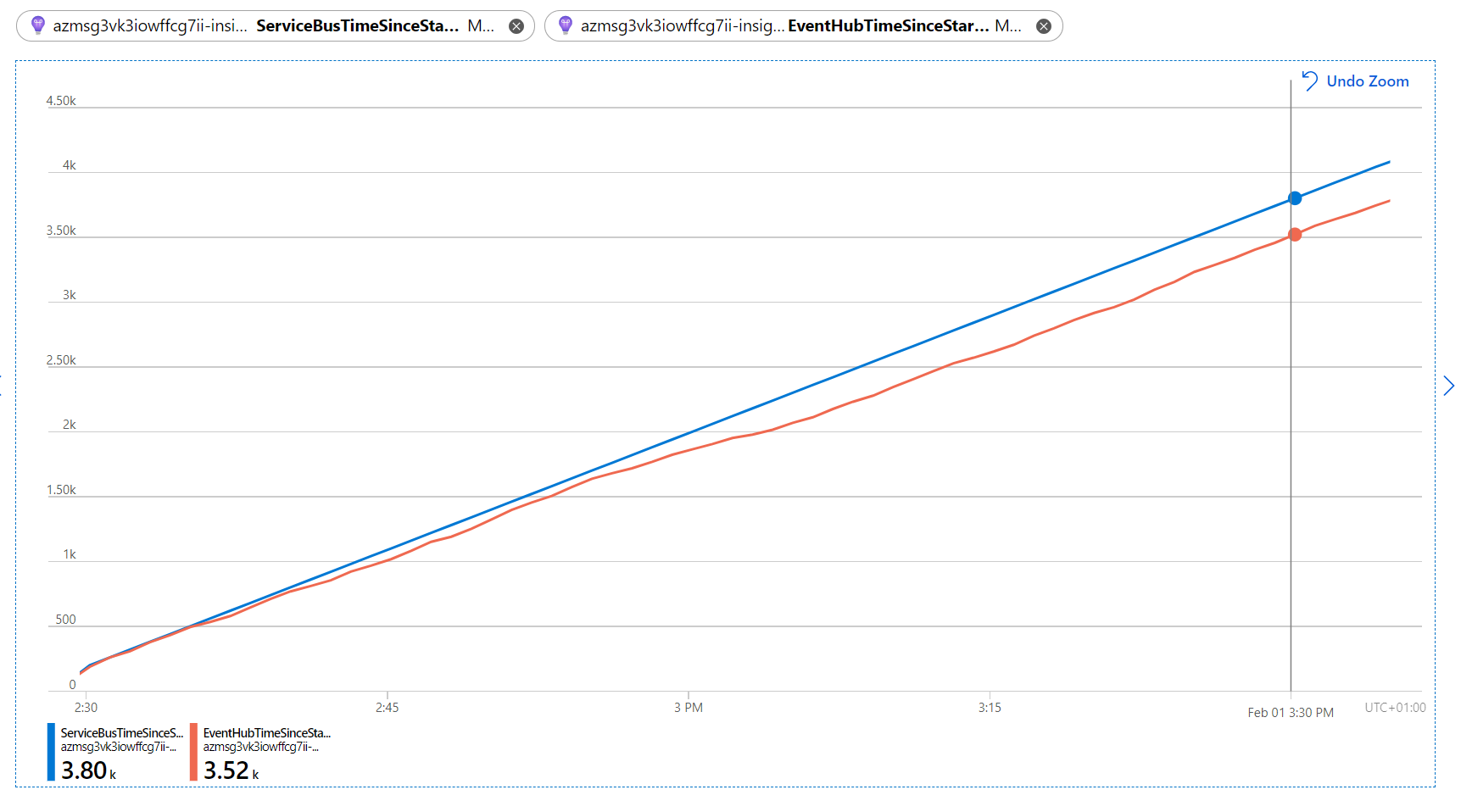
Which tells us, that ServiceBusHandler processes its events perfectly on time, while EventHubHandler has already started lagging behind. This happens because of increased amount of events to be (re)processed, but mostly because of substantial overhead of batches to be retried. If we now remember that Event Hub events have a relatively small retention period and will expire (disappear) after that, then the conclusion will be more or less obvious: a solution like the above doesn’t look too much reliable.
The workaround in this particular case could of course be to decrease the batch size, so that the batch doesn’t get reverted that often. Or to properly handle all potential exceptions, which in practice might require evolving your own custom retry and dead-lettering logic, to ensure that each and every event is processed successfully.
Lesson learned: it is very important to understand the difference between Delivery Guarantee and Processing Guarantee, and be precisely sure about which type of guarantee you would like to see in your solution. Historically Event Streaming platforms like Azure Event Hubs were intended for… well, massive event streaming and stream analytics, in which case processing of a single particular event is supposed to be done on a best-effort basis. Later on they did matured with features to ensure reliable delivery, but those features might still be not enough for you to achieve reliable processing. Plus, don’t forget about Event Hubs retention period, which is never infinite, so if your processing pipeline is for whatever reason not fast enough, eventually it will simply start losing events - and that undermines the whole idea of reliability, doesn’t it?
Questions, concerns or objections? Let’s discuss them via Twitter!